IT
IT  RU
RU 40
40
Ogni rete neurale, una volta creata, deve essere addestrata. Senza addestramento, ottenere un risultato corretto è poco probabile. Esistono diversi metodi per addestrare una rete neurale.
Tra questi, tre approcci sono particolarmente rilevanti: la retropropagazione, la retropropagazione resiliente e l'algoritmo genetico.
Metodo di retropropagazione
Questo metodo, noto anche come Backpropagation, è uno dei principali perché si basa sull'algoritmo della discesa del gradiente. Muovendosi lungo il gradiente, il modello cerca minimi e massimi locali della funzione. Capire questo approccio rende molto più semplice comprendere il metodo successivo.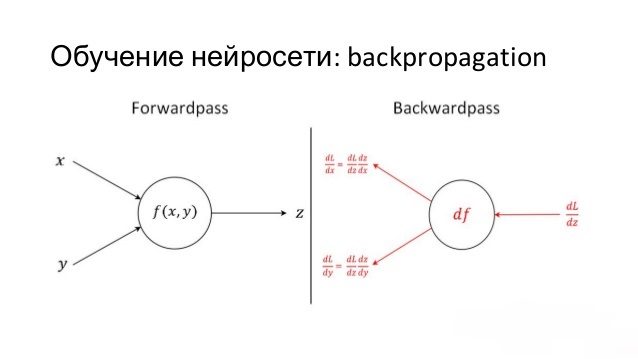
Se immaginiamo la funzione come un grafico che descrive la dipendenza dell'errore dal peso di una sinapsi, su quel grafico bisogna individuare il punto con il valore minimo dell'errore e quello con il valore massimo. Ogni peso ha una propria rappresentazione grafica e, per ciascuno, occorre calcolare il minimo globale.
Il gradiente è un vettore che indica la direzione e la pendenza della discesa. Si trova tramite la derivata della funzione nel punto considerato. Si parte da un valore del peso assegnato casualmente, si calcola il gradiente e si sceglie la direzione della discesa. L'operazione si ripete punto dopo punto, finché si raggiunge un minimo locale oltre il quale non si riesce più a scendere.
Per superare questo limite si imposta un valore adeguato del momento, che aiuta ad attraversare una parte del grafico e a raggiungere il punto desiderato. Se il valore è troppo basso, il modello non supera la convessità; se è troppo alto, può oltrepassare il minimo globale.
Oltre al momento di accelerazione, esiste un altro parametro che definisce la velocità generale di apprendimento della rete. Anche questo valore, come il precedente, è un iperparametro e viene scelto per tentativi. Il valore ottimale non è noto in anticipo: si individua solo eseguendo più cicli di addestramento e correggendolo nella direzione opportuna.
Durante l'addestramento, la rete neurale riceve le informazioni e le trasmette in sequenza da un neurone all'altro attraverso le sinapsi. Il flusso arriva allo strato di uscita, dove viene prodotto il risultato. Questo passaggio si chiama propagazione in avanti.
Dopo aver ottenuto il risultato, si calcola l'errore e si esegue il passaggio inverso. In questa fase i pesi delle sinapsi vengono modificati in sequenza, partendo dallo strato di uscita e procedendo verso quello di ingresso. Ogni peso viene aggiornato nella direzione che porta a un risultato migliore.
Per usare questo metodo servono funzioni di attivazione differenziabili. La retropropagazione, infatti, si calcola valutando la differenza tra i risultati e moltiplicandola per la derivata della funzione rispetto al valore in ingresso.
 Per addestrare correttamente la rete, l'errore ottenuto deve essere distribuito su tutti i pesi. Dopo aver calcolato l'errore nello strato di uscita, si può ricavare anche il delta, che verrà trasmesso progressivamente tra i neuroni.
Per addestrare correttamente la rete, l'errore ottenuto deve essere distribuito su tutti i pesi. Dopo aver calcolato l'errore nello strato di uscita, si può ricavare anche il delta, che verrà trasmesso progressivamente tra i neuroni.
Si calcola quindi il gradiente per ogni connessione in uscita. Una volta raccolti tutti i dati necessari, si aggiornano i pesi e, tramite la funzione di retropropagazione, si determina il valore della variazione.
In questa fase non bisogna dimenticare il momento e la velocità di apprendimento.
Una singola iterazione di retropropagazione riduce l'errore solo di una piccola percentuale. Per questo va ripetuta più volte, finché l'indicatore dell'errore si avvicina a 0.
Metodo di retropropagazione resiliente
La Resilient propagation, o Rprop, riduce uno dei limiti della retropropagazione classica: i tempi di addestramento possono diventare elevati, soprattutto quando serve ottenere rapidamente un risultato.
Per accelerare il processo sono stati proposti vari algoritmi aggiuntivi. Rprop è uno di questi.
Questo algoritmo usa come base l'addestramento per epoche e, per correggere i coefficienti di peso, considera solo il segno delle derivate parziali. La dimensione della correzione del peso viene calcolata secondo una regola specifica.
Se in questa fase la derivata cambia segno, significa che la variazione è stata troppo ampia: il minimo locale è stato superato. Bisogna quindi tornare indietro, riportare il peso alla posizione precedente e ridurre l'ampiezza della modifica.
Se invece il segno della derivata non cambia, la variazione del peso viene aumentata per migliorare la convergenza.
Fissando i parametri principali di correzione dei pesi, si può evitare la regolazione dei parametri globali. Questo è un altro vantaggio del metodo rispetto alla retropropagazione classica. Per tali parametri esistono valori consigliati, ma non ci sono vincoli rigidi sulla loro scelta.
Per evitare che il peso assuma valori troppo grandi o troppo piccoli, si introducono limiti alla dimensione della correzione. Anche il valore della correzione viene calcolato secondo una regola definita.
Se la derivata della funzione in un punto specifico cambia segno da positivo a negativo, l'errore sta aumentando: il peso deve essere corretto e viene ridotto. Nel caso opposto viene aumentato.
Il procedimento parte dall'inizializzazione della correzione. Poi si calcolano le derivate parziali, si ricava il nuovo valore di correzione e si aggiornano i pesi. Se la condizione di arresto non è soddisfatta, l'algoritmo torna al calcolo delle derivate e ripete il ciclo. In questo modo la rete neurale può convergere molto più rapidamente rispetto al metodo precedente.
Algoritmo genetico
Il terzo metodo interessante per addestrare reti neurali artificiali è il Genetic Algorithm. Si tratta di una versione semplificata di un meccanismo naturale, basato sull'incrocio dei risultati. In pratica, i risultati vengono combinati, si selezionano i migliori e da essi si genera una nuova popolazione.
Se il risultato non è soddisfacente, l'algoritmo continua finché la generazione non diventa adeguata. Può anche terminare senza raggiungere il risultato desiderato, se si esaurisce il numero di tentativi o il tempo dedicato alla mutazione. Questo algoritmo può essere applicato all'ottimizzazione dei pesi di una rete neurale con topologia predefinita.
In questo caso il peso viene codificato in binario e ogni risultato è definito dall'insieme completo dei pesi. La qualità viene valutata calcolando l'errore in uscita.
Il video marketing aiuta ad attirare clienti e a promuovere un prodotto.
Per compilare correttamente uno snippet, leggi il nostro articolo.
Trovi consigli per scrivere un buon articolo qui.
Altre varianti di addestramento
Oltre ai metodi descritti, esistono anche varianti di addestramento delle reti neurali supervisionate e non supervisionate. L'apprendimento supervisionato si applica soprattutto a regressione e classificazione.
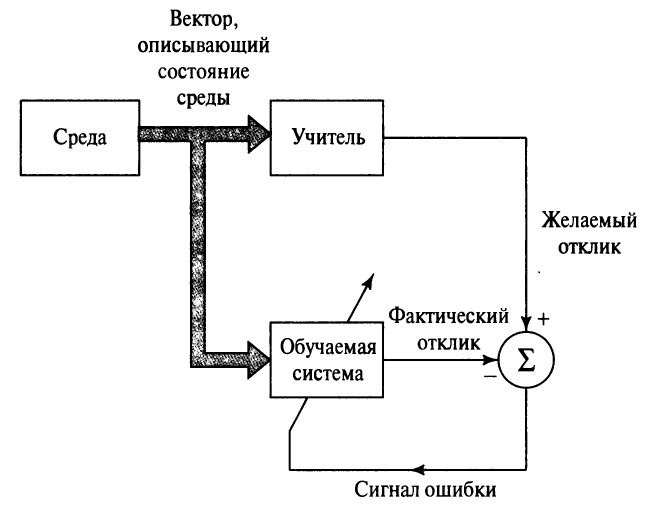 In questo caso il supervisore fornisce gli esempi, mentre la rete svolge il ruolo del modello da addestrare. Il supervisore indica i dati in ingresso e il risultato atteso, così la rete capisce verso quale output deve tendere con i parametri dati.
In questo caso il supervisore fornisce gli esempi, mentre la rete svolge il ruolo del modello da addestrare. Il supervisore indica i dati in ingresso e il risultato atteso, così la rete capisce verso quale output deve tendere con i parametri dati.
L'apprendimento non supervisionato funziona in modo diverso ed è meno frequente. In questo scenario la rete neurale non riceve il risultato desiderato. Questo tipo di addestramento è adatto alle reti incaricate di raggruppare dati in cluster secondo parametri definiti. Analizzando un grande volume di dati in ingresso, la rete li divide in categorie in base a determinate caratteristiche.
L'apprendimento per rinforzo si usa quando è possibile valutare il risultato finale prodotto dalla rete.
Premiando la rete neurale ogni volta che il risultato ottenuto si avvicina il più possibile a quello desiderato, le si permette di cercare autonomamente diverse soluzioni al problema, finché continua a produrre risultati utili.
In questo modo la rete cerca i percorsi migliori per raggiungere l'obiettivo senza ricevere dati dal supervisore.
Esistono anche altri metodi di addestramento:
- il metodo stocastico può essere riassunto così: appena viene trovata una variazione di aggiornamento, si aggiorna subito il peso corrispondente;
- il metodo batch somma i valori di tutte le variazioni in un ciclo specifico e aggiorna i pesi solo al termine. Questo fa risparmiare molto tempo, ma può ridurre la precisione;
- il metodo mini-batch combina i vantaggi dei due approcci precedenti: i pesi vengono distribuiti liberamente in gruppi selezionati e modificati in base alla somma dei coefficienti di correzione di tutti i pesi del gruppo.
In qualsiasi processo di addestramento si usano iperparametri scelti manualmente, che non sono variabili di una specifica equazione. Tra questi rientrano il momento e la velocità di apprendimento già citati.
Si possono includere anche il numero di strati nascosti, il numero di neuroni in ogni strato, la presenza o l'assenza di neuroni di bias. Gli iperparametri dipendono soprattutto dal tipo di rete neurale artificiale. La scelta corretta dei loro valori influisce direttamente sulla convergenza della rete.
Quando l'addestramento si prolunga troppo, può comparire il rischio di overfitting. Di solito accade quando la rete riceve troppi dati e smette di generalizzare: invece di apprendere, memorizza i risultati per uno specifico insieme di parametri in ingresso. Con nuovi parametri, il rumore nei dati può peggiorare la capacità di generalizzazione e influire sull'output.
Per evitarlo, l'addestramento deve essere eseguito su dati in ingresso diversi e sufficientemente distanti tra loro.
Le reti neurali sono un ambito di sviluppo molto promettente. Una volta creata una rete neurale, è possibile addestrarla a svolgere molti compiti, compresi quelli che una persona esegue in modo inconscio e di cui non conosce l'algoritmo esatto.
Le reti neurali vengono spesso considerate un analogo del cervello umano. In parte può essere vero, ma resta una copia che somiglia solo lontanamente al suo prototipo.
 28.167 visualizzazioni
28.167 visualizzazioni Discuti
Discuti 9 minuti di lettura
9 minuti di lettura 22/05/2026, 12:14
22/05/2026, 12:14


 Siti
Siti Pagine
Pagine Video
Video
.5242c455a0303b436d68.svg)
.d6289f37f1093c657798.svg)

.bf739e4e9fd1c7bfdfa4.png)